Experts from Google and Sakana unveiled two cutting-edge neuronal network patterns in recent weeks that could revolutionize the AI sector.
These innovations challenge the supremacy of transformers, a type of neural network that connects inputs and outputs based on context, the technology that has for the past six years defined AI.
The innovative techniques are Google’s” Titans”, and” Transformers Squared”, which was designed by Sakana, a Tokyo AI company known for using characteristics as its design for it options. In fact, both Google and Sakana studied the human mind and addressed the winding issue. Instead of re-interrupting the entire model for every problem, their transformers generally use various memory stages and separately activate various expert modules.
Without being actually bigger or more expensive to operate, AI systems become smarter, faster, and more flexible than ever before.
For context, motor infrastructure, the technologies which gave ChatGPT the’ T’ in its title, is designed for sequence-to-sequence tasks like as vocabulary modeling, translation, and image processing. To design dependencies between type tokens in horizontal rather than simultaneously, transformers rely on “attention mechanisms,” or tools to comprehend how important a strategy is depending on a perspective, to use recurrent neural networks, the main AI systems before transformers became available. This innovation provided environment knowing to models and established a before and after time in the development of AI.
Nevertheless, despite their extraordinary success, converters faced significant challenges in flexibility and agility. For types to be more flexible and adaptable, they also need to be more effective. Therefore, when trained, they may be improved until developers create a new model or customers rely on third-party tools. That’s why now, in AI, “bigger is better” is a basic guideline.
But this may change rapidly, thanks to Google and Sakana.
Titans: A fresh storage infrastructure for naive AI
Google Research’s Titans infrastructure takes a unique approach to improving AI resilience. Titans focuses on altering how types shop and access information rather than altering how designs process it. Similar to how people memory operates, the infrastructure introduces a neurological long-term memory unit that learns to learn at exam time.
Now, models read your entire swift and productivity, predict a key, read everything again, forecast the future token, and so on until they come up with the answer. They have an incredible short-term memory, but they suck at long-term memory. Ask them to remember things that are outside their context window or very specific information in a lot of noise, and they will probably fail.
Titans, on the other hand, combines three types of memory systems: short-term memory ( similar to traditional transformers ), long-term memory ( for storing historical context ), and persistent memory ( for task-specific knowledge ). This multi-tiered approach makes it possible for the model to handle sequences that are longer than 2 million tokens, which is far beyond what current transformers can process effectively.
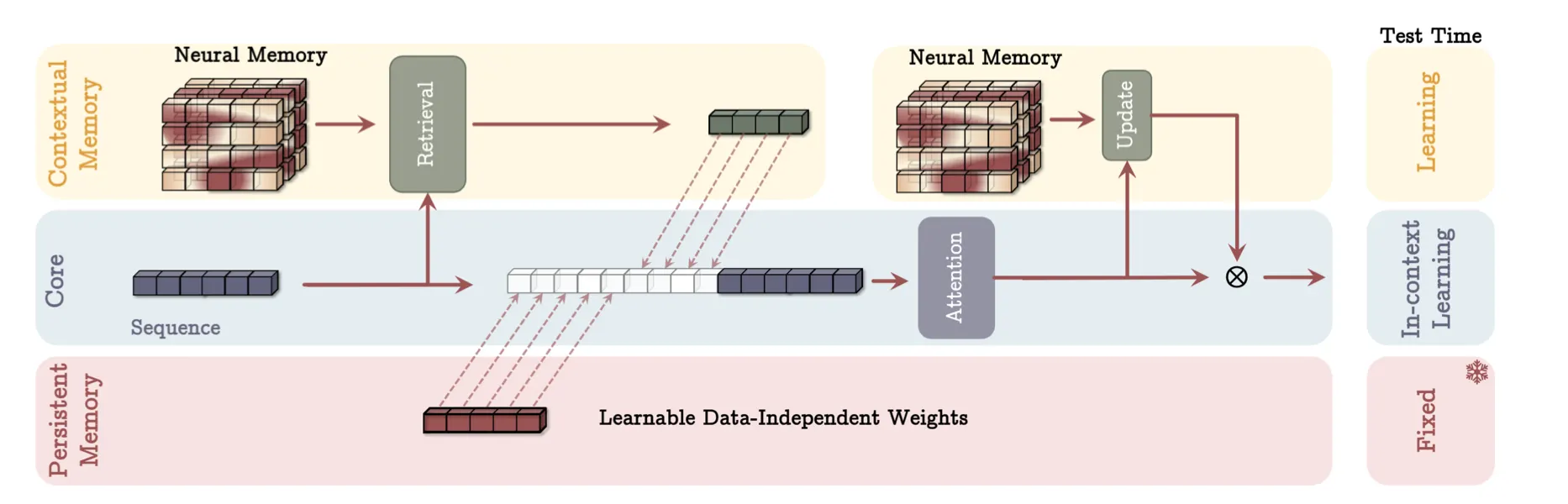
According to the research paper, Titans shows significant improvements in various tasks, including language modeling, common-sense reasoning, and genomics. The architecture has proven particularly effective at “needle-in-haystack” tasks, where it needs to locate specific information within very long contexts.
The system dynamically reconfigures its networks in response to changing demands, mimicking how the human brain activates particular regions for various tasks.
Titans exemplify this idea by incorporating interconnected memory systems, similar to how different brain regions are specialized for distinct functions and are activated based on the task being performed. These systems ( short-term, long-term, and persistent memories ) work together to dynamically store, retrieve, and process information based on the task at hand.
Transformer Squared: Self-adapting AI is here
A team of researchers from Sakana AI and the Institute of Science Tokyo released Transformer Squared, a framework that enables AI models to modify their behavior in real-time based on the task at hand, just two weeks after Google published the article. More effective than traditional fine-tuning techniques, the system works by selectively changing only the single components of its weight matrices during inference.
Transformer Squared “employs a two-pass mechanism: first, a dispatch system identifies the task properties, and then task-specific’ expert’ vectors, trained using reinforcement learning, are dynamically mixed to obtain targeted behavior for the incoming prompt”, according to the research paper.
It gives up more time thinking for its specialization ( knowing which expertise to apply ).

Transformer Squared is particularly innovative because it can adapt without having to go through a lot of retraining. The system employs Singular Value Fine-tuning ( SVF), a technique described by researchers as” SVF,” to only modify the essential elements for a particular task. Comparing current techniques to current methods, this approach significantly lowers computational demands while maintaining or improving performance.
In testing, Sakana’s Transformer demonstrated remarkable versatility across different tasks and model architectures. The framework demonstrated particular promise in handling applications that were not distributed, which suggests it might help AI systems become more adaptable and adaptable to novel circumstances.
Here’s our attempt at an analogy. When learning a new skill without having to rewire everything, your brain creates new neural connections. When you learn to play piano, for instance, your brain doesn’t need to rewrite all its knowledge—it adapts specific neural circuits for that task while maintaining other capabilities. Sakana’s idea was that developers don’t need to retrain the model’s entire network to adapt to new tasks.
Instead, the model selectively adjusts specific components ( through Singular Value Fine-tuning ) to become more effective at particular tasks while still maintaining its general capabilities.
Overall, the days of AI companies boasting about how big their models are might soon be forgotten. Future models won’t need to rely on massive scales to achieve greater versatility and performance if this new generation of neural networks gains traction.
Today, transformers dominate the landscape, often supplemented by external tools like Retrieval-Augmented Generation (RAG ) or LoRAs to enhance their capabilities. But in the fast-moving AI industry, it only takes one breakthrough implementation to set the stage for a seismic shift—and once that happens, the rest of the field is sure to follow.
Generally Intelligent Newsletter
A generative AI model’s generative AI model, Gen, tells a weekly AI journey.


